[SRE] クエリパフォーマンステスト
本記事では、PostgreSQLデータベース環境におけるクエリのパフォーマンステストを扱います。本テストを通じて、同一のハードウェア環境下でさまざまなSQLクエリがどのように動作するかを検証します。記事を読むことで、SQLクエリのパフォーマンステストの実施方法や、クエリ構造ごとのパフォーマンスの違いを理解できるでしょう。
PostgreSQLのインストール方法
PostgreSQLはDockerを利用してインストールしました。サービスのセットアップには、以下の docker-compose.yml ファイルを使用しています。
services:
postgres:
image: postgres:latest
container_name: postgres-sre
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
POSTGRES_DB: imdb
ports:
- "54321:5432"
volumes:
- ../data:/data
cpus: 2.0
mem_limit: 4g使用データセット
本テストではIMDbデータセットを使用しました。パフォーマンステストにはシンプルなサンプルデータでは不十分なため、フルデータセットを利用しています。このデータセットには映画、テレビ番組、その他のメディアに関するタイトル、公開日、ジャンル、評価などの情報が含まれています。
データセットはTSV形式で提供されており、以下のリンクからダウンロード可能です。
- データソース: IMDBデータセットのTSVファイルをPostgreSQLにインポート
- スキーマ参照: テーブル構造とリレーションはIMDB Non-Commercial Datasetsの仕様に準拠
- データ特徴:
- 数百万件規模の本番データセット
- 複雑かつ多階層のリレーショナル構造
- 現実的なデータ分布と制約
- クエリパフォーマンステストに最適な実データ環境を提供
テストしたクエリの種類
以下のクエリタイプを用いて、パフォーマンスを検証しました(詳細なSQLは下記に記載)。
- 単純なSELECT: 主キーによる単一行の検索
- パターンマッチ(ILIKE): ワイルドカードによる大文字・小文字区別なしの検索
- JOIN: 複数テーブルの結合によるデータ取得
- 複合条件・グループ化: 複数条件・GROUP BYによる集計
- 複数テーブルJOIN: テーブル横断での件数集計
- サブクエリ: 結果の絞り込みのためのサブクエリ利用
- CTE(共通テーブル式): CTEによる集計とフィルタリング
- ウィンドウ関数:
ROW_NUMBER()などのウィンドウ関数によるグループ内ランキング
単純なSELECT
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
title_basics
WHERE
tconst = 'tt1234567';このクエリは、title_basicsテーブルから主キーtconstを利用して1行だけ取得します。主キーインデックスが自動的に生成されるため、パフォーマンスは非常に良好です。実行時間は'0.045 ms'でした。
パターンマッチ(ILIKE)
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE INDEX idx_primarytitle_trgm ON title_basics USING gin (primarytitle gin_trgm_ops);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
title_basics
WHERE
primaryTitle ILIKE '%naruto%'
LIMIT
100;このクエリは、primaryTitleカラムが'naruto'を含む行を、大文字・小文字を区別せずに検索します。ILIKE '%keyword%' は通常フルテーブルスキャンとなり、大規模テーブルでは非常に遅くなります。
しかし、pg_trgm拡張のGINインデックスを作成することで、文字列をトライグラム(三文字単位)で分割し、インデックスを利用して候補行を高速に絞り込めます。その結果、インデックスなしで2,400msだったクエリが、インデックス利用時は3msで完了しました。
JOIN: 高評価映画TOP100
CREATE INDEX idx_ratings_averagerating_desc ON title_ratings (averageRating DESC);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
b.tconst,
b.primaryTitle,
r.averageRating
FROM
title_basics b
JOIN title_ratings r ON b.tconst = r.tconst
WHERE
b.titleType = 'movie'
ORDER BY
r.averageRating DESC
LIMIT
100;このクエリは、title_basicsとtitle_ratingsテーブルを結合し、評価が高い映画上位100件を取得します。averageRatingのインデックスで並び替え処理を最適化しています。インデックスがない場合300msかかっていたものが、インデックス追加で100msに短縮されました。JOINや並び替えを伴うクエリでは、適切なインデックス設計がパフォーマンス改善の鍵となります。
複合条件・GROUP BY: ジャンル・年別映画数
CREATE INDEX idx_basics_type_year_tconst ON title_basics (titleType, startYear, tconst);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
b.genres,
b.startYear,
COUNT(*) AS movie_count,
AVG(r.averageRating) AS avg_rating
FROM
title_basics b
JOIN title_ratings r ON b.tconst = r.tconst
WHERE
b.titleType = 'movie'
AND b.startYear BETWEEN 2010
AND 2020
GROUP BY
b.genres,
b.startYear
ORDER BY
movie_count DESC;このクエリは、2010年から2020年に公開された映画をジャンル・年ごとに集計し、平均評価も算出します。インデックスなしで800ms、インデックスありで600msに短縮されました。
ただし、大規模なテーブルや複雑なJOINがあるGROUP BYクエリでは、インデックスがあってもメモリやディスク上での集計・ソートがボトルネックになりやすいです。パフォーマンス改善のためには、事前集計テーブルやマテリアライズドビュー、OLAP系DBの活用も検討しましょう。
複数テーブルJOIN
CREATE INDEX idx_basics_type_tconst ON title_basics (titleType, tconst);
CREATE INDEX idx_crew_tconst ON title_crew (tconst);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
c.directors,
COUNT(*) AS film_count
FROM
title_crew c
JOIN title_basics b ON c.tconst = b.tconst
WHERE
b.titleType = 'movie'
GROUP BY
c.directors
ORDER BY
film_count DESC
LIMIT
10;(本クエリの実行計画・詳細結果は割愛)
サブクエリ: 特定俳優のフィルモグラフィー
CREATE INDEX idx_name_primaryname ON name_basics (primaryName);
CREATE INDEX idx_principals_nconst ON title_principals (nconst);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
b.primaryTitle
FROM
title_basics b
WHERE
b.tconst IN (
SELECT
p.tconst
FROM
title_principals p
WHERE
p.nconst = (
SELECT
n.nconst
FROM
name_basics n
WHERE
n.primaryName = 'Tom Hanks'
LIMIT
1
)
);このクエリは、特定俳優(例:Tom Hanks)の出演作品をサブクエリで抽出します。primaryNameとnconstのインデックスで高速化を図ります。インデックスなしで15,500ms、インデックスありで250msに短縮されました。サブクエリ自体がパフォーマンス低下の原因とは限らず、重要なのは頻繁に参照されるカラムへのインデックス設計です。
CTE(共通テーブル式): 年別映画数
CREATE INDEX idx_basics_type_year ON title_basics (titleType, startYear);
EXPLAIN (ANALYZE, BUFFERS) WITH yearly_counts AS (
SELECT
startYear,
COUNT(*) AS cnt
FROM
title_basics
WHERE
titleType = 'movie'
GROUP BY
startYear
)
SELECT
*
FROM
yearly_counts
WHERE
startYear >= 2000
ORDER BY
cnt DESC;このクエリはCTE(WITH句)を使い、2000年以降に公開された映画の年別件数を集計します。titleType, startYearの複合インデックスで550msから40msまで短縮されました。
ウィンドウ関数: 年ごとの最高評価映画
CREATE INDEX idx_basics_type_year_tconst ON title_basics (titleType, startYear, tconst);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
(
SELECT
b.startYear,
b.primaryTitle,
r.averageRating,
ROW_NUMBER() OVER (
PARTITION BY b.startYear
ORDER BY
r.averageRating DESC
) AS rn
FROM
title_basics b
JOIN title_ratings r ON b.tconst = r.tconst
WHERE
b.titleType = 'movie'
AND b.startYear IS NOT NULL
) sub
WHERE
rn = 1
ORDER BY
startYear;このクエリは、ウィンドウ関数(ROW_NUMBER())で各年ごとに最高評価の映画を抽出します。インデックスなしで1,000ms、インデックスありで5msになりましたが、ウィンドウ関数・ORDER BY・GROUP BYを含むクエリは、インデックスがあっても全件走査や大規模なソートが必要となる場合があります。
本格的な集計・分析には、事前集計やOLAP製品の導入も検討しましょう。
まとめ
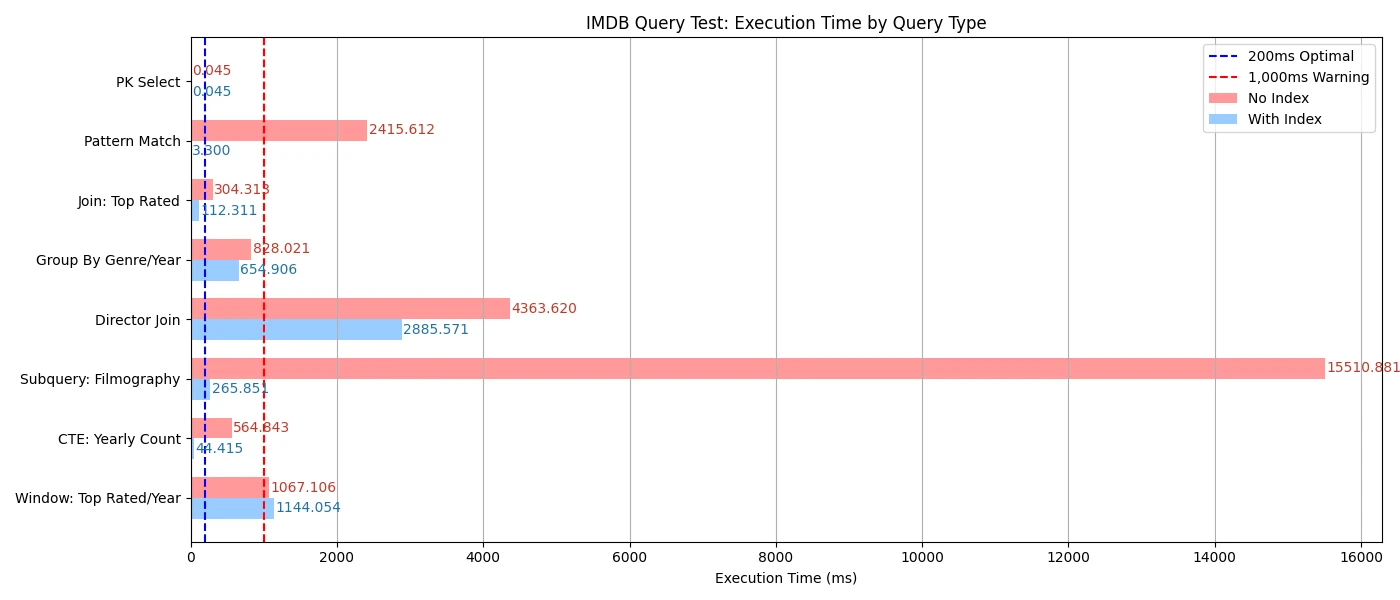
ご覧の通り、インデックス設計はPostgreSQLのクエリパフォーマンス最適化において非常に重要です。 頻繁に参照するカラムに適切なインデックスを作成することで、シンプルな検索だけでなく、JOINや集計クエリの実行時間を大幅に短縮できます。
一方で、複雑な集計やウィンドウ関数を使ったクエリは、インデックスを設計しても遅くなる場合があります。その場合、事前集計・マテリアライズドビュー・OLAP等の手法を組み合わせて、パフォーマンス改善を図りましょう。
本記事では、IMDbデータセットを使ったPostgreSQL環境でのクエリパフォーマンステスト手法や、各種SQLクエリの実行特性を紹介しました。これらの知見を活用し、データベースアクセスやアプリケーションパフォーマンスの最適化に役立ててください。
テストに使用した全データ・コード・実行結果(README.md内に英語で記載)は、下記リポジトリで公開しています:
次回の記事では、さらに多様なインデックス戦略・最適化手法について解説予定です。今後もデータベースパフォーマンス最適化の最新トピックをお楽しみに!
