[SRE] 쿼리 성능 테스트
이 글에서는 PostgreSQL 데이터베이스 환경에서 쿼리 성능 테스트를 진행한 내용을 다룹니다.
동일한 하드웨어 환경에서 다양한 SQL 쿼리가 실제로 어떻게 동작하는지, 그리고 쿼리 구조별로 성능 차이가 어떻게 발생하는지 살펴봅니다.
이 글을 통해 SQL 쿼리 성능 테스트 방법과 쿼리 구조별 성능 차이를 이해할 수 있습니다.
PostgreSQL 설치 방법
PostgreSQL는 Docker를 이용해 설치했습니다.
아래의 docker-compose.yml 파일로 서비스를 구성할 수 있습니다.
services:
postgres:
image: postgres:latest
container_name: postgres-sre
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
POSTGRES_DB: imdb
ports:
- "54321:5432"
volumes:
- ../data:/data
cpus: 2.0
mem_limit: 4g사용한 데이터셋
이번 테스트에는 IMDb 데이터셋을 사용했습니다. 성능 테스트에는 단순 샘플 데이터만으로는 충분하지 않기 때문에, IMDb의 전체 데이터셋을 다운로드하여 사용했습니다. 이 데이터셋에는 영화, TV 프로그램 등 다양한 미디어의 제목, 출시일, 장르, 평점 등 정보가 포함되어 있습니다.
데이터셋은 TSV 포맷으로 제공되며, 아래 링크에서 다운로드할 수 있습니다.
- 데이터 소스 : IMDB 데이터셋의 TSV 파일을 PostgreSQL에 적재
- 스키마 참조 : 테이블 구조와 관계는 IMDB Non-Commercial Datasets 공식 문서 기준
- 데이터 특징 :
- 수백만 건 규모의 대용량 데이터셋
- 복잡하고 계층적인 관계형 구조
- 실제와 유사한 데이터 분포 및 제약 조건
- 쿼리 성능 평가에 최적화된 현실적인 환경 제공
테스트한 쿼리 유형
다음과 같은 쿼리 유형별로 성능을 비교하였습니다. (자세한 SQL 예시는 아래에 첨부)
- 단순 SELECT: 기본키(PK)로 한 행만 조회
- 패턴 매칭(ILIKE): 대소문자 구분 없는 와일드카드 검색
- JOIN: 여러 테이블 조인하여 데이터 조회
- 복합 조건 및 그룹화: 여러 조건, GROUP BY 기반 집계
- 다중 테이블 JOIN: 여러 테이블을 엮어서 건수 집계
- 서브쿼리: 서브쿼리로 결과를 필터링
- CTE(공통 테이블 식): CTE 기반 집계 및 필터링
- 윈도우 함수:
ROW_NUMBER()등 윈도우 함수로 그룹 내 순위 구하기
단순 SELECT
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
title_basics
WHERE
tconst = 'tt1234567';이 쿼리는 title_basics 테이블에서 기본키(tconst)로 한 행만 조회합니다.
PostgreSQL은 PK 제약조건이 있으면 자동으로 인덱스를 생성하므로, 성능이 매우 뛰어납니다.
실행 시간은 약 '0.045 ms'였습니다.
패턴 매칭 (ILIKE)
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE INDEX idx_primarytitle_trgm ON title_basics USING gin (primarytitle gin_trgm_ops);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
title_basics
WHERE
primaryTitle ILIKE '%naruto%'
LIMIT
100;이 쿼리는 primaryTitle 컬럼에 'naruto'가 포함된 행을 대소문자 구분 없이 찾습니다.
ILIKE '%keyword%'는 일반적으로 전체 테이블을 스캔해야 하므로, 대용량 테이블에서 매우 느릴 수 있습니다.
하지만 pg_trgm 확장 기능의 GIN 인덱스를 만들면, 문자열을 트라이그램(3글자 단위)로 쪼개서 인덱싱하여 후보 행을 매우 빠르게 찾을 수 있습니다.
실제로 인덱스 없이 2,400ms, 인덱스 적용 후 3ms로 대폭 단축되었습니다.
JOIN: 평점 상위 영화 100건
CREATE INDEX idx_ratings_averagerating_desc ON title_ratings (averageRating DESC);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
b.tconst,
b.primaryTitle,
r.averageRating
FROM
title_basics b
JOIN title_ratings r ON b.tconst = r.tconst
WHERE
b.titleType = 'movie'
ORDER BY
r.averageRating DESC
LIMIT
100;이 쿼리는 title_basics와 title_ratings를 조인하여, 평점이 높은 영화 100건을 가져옵니다.
averageRating에 인덱스를 만들면 정렬(ORDER BY) 성능이 크게 향상됩니다.
인덱스 없이 약 300ms, 인덱스 적용 후 100ms로 단축되었습니다.
조인이나 정렬이 들어간 쿼리는 인덱스 설계가 매우 중요합니다.
복합 조건 및 GROUP BY: 장르/연도별 영화 건수
CREATE INDEX idx_basics_type_year_tconst ON title_basics (titleType, startYear, tconst);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
b.genres,
b.startYear,
COUNT(*) AS movie_count,
AVG(r.averageRating) AS avg_rating
FROM
title_basics b
JOIN title_ratings r ON b.tconst = r.tconst
WHERE
b.titleType = 'movie'
AND b.startYear BETWEEN 2010
AND 2020
GROUP BY
b.genres,
b.startYear
ORDER BY
movie_count DESC;이 쿼리는 2010~2020년 개봉 영화를 장르·연도별로 집계하고, 각 그룹의 평균 평점도 계산합니다. 인덱스 없이 800ms, 인덱스 적용 후 600ms까지 줄어듭니다.
하지만 대용량 데이터에서 GROUP BY와 다중 JOIN이 결합된 쿼리는, 인덱스가 있어도 메모리/디스크 집계와 정렬 과정이 병목이 되기 쉽습니다. 이럴 땐 사전 집계 테이블, 마테리얼라이즈드 뷰, OLAP 계열 DB를 적극적으로 활용하는 것이 좋습니다.
다중 테이블 JOIN
CREATE INDEX idx_basics_type_tconst ON title_basics (titleType, tconst);
CREATE INDEX idx_crew_tconst ON title_crew (tconst);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
c.directors,
COUNT(*) AS film_count
FROM
title_crew c
JOIN title_basics b ON c.tconst = b.tconst
WHERE
b.titleType = 'movie'
GROUP BY
c.directors
ORDER BY
film_count DESC
LIMIT
10;(해당 쿼리의 상세 실행 계획과 결과는 생략합니다.)
서브쿼리: 특정 배우의 필모그래피
CREATE INDEX idx_name_primaryname ON name_basics (primaryName);
CREATE INDEX idx_principals_nconst ON title_principals (nconst);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
b.primaryTitle
FROM
title_basics b
WHERE
b.tconst IN (
SELECT
p.tconst
FROM
title_principals p
WHERE
p.nconst = (
SELECT
n.nconst
FROM
name_basics n
WHERE
n.primaryName = 'Tom Hanks'
LIMIT
1
)
);이 쿼리는 특정 배우(예: Tom Hanks)가 출연한 모든 작품을 서브쿼리로 찾아냅니다.
primaryName과 nconst에 인덱스를 추가하면, 15,500ms → 250ms로 성능이 개선됩니다.
서브쿼리가 반드시 느린 건 아니며, 핵심은 자주 조회되는 컬럼에 인덱스를 잘 설계하는 것입니다.
CTE(공통 테이블 식): 연도별 영화 수 집계
CREATE INDEX idx_basics_type_year ON title_basics (titleType, startYear);
EXPLAIN (ANALYZE, BUFFERS) WITH yearly_counts AS (
SELECT
startYear,
COUNT(*) AS cnt
FROM
title_basics
WHERE
titleType = 'movie'
GROUP BY
startYear
)
SELECT
*
FROM
yearly_counts
WHERE
startYear >= 2000
ORDER BY
cnt DESC;이 쿼리는 CTE(WITH 구문)를 이용해, 2000년 이후 개봉 영화의 연도별 집계 건수를 구합니다.
복합 인덱스(titleType, startYear)를 만들면 550ms → 40ms로 개선됩니다.
윈도우 함수: 연도별 최고 평점 영화
CREATE INDEX idx_basics_type_year_tconst ON title_basics (titleType, startYear, tconst);
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
(
SELECT
b.startYear,
b.primaryTitle,
r.averageRating,
ROW_NUMBER() OVER (
PARTITION BY b.startYear
ORDER BY
r.averageRating DESC
) AS rn
FROM
title_basics b
JOIN title_ratings r ON b.tconst = r.tconst
WHERE
b.titleType = 'movie'
AND b.startYear IS NOT NULL
) sub
WHERE
rn = 1
ORDER BY
startYear;이 쿼리는 윈도우 함수(ROW_NUMBER())를 활용해, 연도별로 가장 높은 평점을 받은 영화를 추출합니다.
인덱스 없이 1,000ms, 인덱스 적용 후 5ms로 줄었지만,
윈도우 함수나 GROUP BY, ORDER BY가 포함된 쿼리는 모든 행을 스캔하고 정렬하는 과정이 생략되지 않으므로
특히 대용량 데이터에서는 여전히 병목이 될 수 있습니다.
실시간 대규모 분석에는 사전 집계나 OLAP 활용이 필요할 수 있습니다.
결론
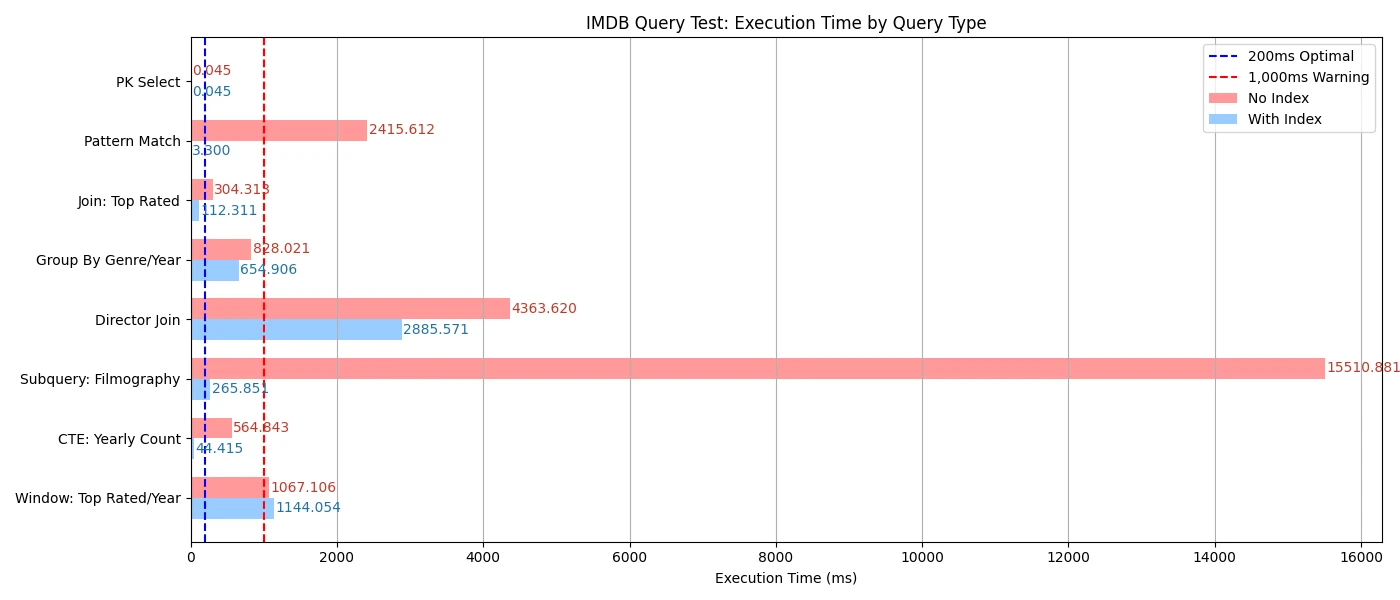
보시다시피, 인덱스 설계는 PostgreSQL 쿼리 성능 최적화에서 매우 중요한 역할을 합니다. 자주 조회되는 컬럼에 적절하게 인덱스를 설계하면, 단순 조회뿐만 아니라 조인, 집계 쿼리의 실행 시간도 크게 단축할 수 있습니다.
반면, 집계나 윈도우 함수처럼 본질적으로 리소스를 많이 쓰는 쿼리는 인덱스를 잘 만들어도 느려질 수 있으며, 이 경우에는 마테리얼라이즈드 뷰, 사전 집계, OLAP 등의 보완 전략이 필요합니다.
이 글에서는 IMDb 데이터셋을 활용해 PostgreSQL 환경에서 쿼리 성능 테스트를 진행하고, 각 쿼리 유형별 실행 특성을 직접 실험한 결과를 소개했습니다. 이런 경험과 결과가, 데이터베이스 성능 개선과 시스템 최적화에 도움이 되시길 바랍니다.
실험에 사용한 전체 코드/데이터/쿼리 결과(README.md에 영어로 정리)는 아래 깃허브에서 확인할 수 있습니다.
다음 포스팅에서는 다양한 인덱스 전략과 실전 최적화 노하우를 더 깊이 다룰 예정입니다. 많은 관심 부탁드립니다!
